Dear Support Team,
I am writing to report a critical issue affecting our use of DeepSeek-R1 through the SambaNova OpenAI-API-compatible interface on the Dify platform.
During regular usage, the model’s responses frequently truncate mid-output (e.g., stopping abruptly mid-sentence or paragraph), severely disrupting user workflows. This occurs consistently across various queries and use cases, suggesting a systemic problem rather than isolated incidents.
Key details:
This issue significantly degrades user experience and hampers productivity. We suspect potential causes may include:
-
Timeout thresholds in the API gateway or proxy.
-
Token limits or streaming configuration mismatches.
-
Network instability between Dify and SambaNova endpoints.
Requested Actions:
-
Investigate server-side logs for timeout/termination triggers.
-
Verify streaming protocol compatibility between Dify/SambaNova/DeepSeek-R1.
-
Recommend optimal settings (e.g., max_tokens, timeouts) to prevent truncation.
We urgently seek your assistance to resolve this. Please let us know if additional details (e.g., sample requests, error logs) are required.
Thank you for your prompt attention.
Thanks for reporting this issue. Could you please share a few example prompts, the full request payload (including model, max_tokens, stream, etc.), and the approximate timestamp (UTC) when the issue occurred? This will help us replicate and check backend logs.
Thank you for reply, the finish reason is length.
So that SambaNova’s DeepSeek-R1 can only use around 12k tokens at a time? Are there any adjustable settings I might have missed?
“usage”: {
“prompt_tokens”: 7604,
“prompt_unit_price”: “0”,
“prompt_price_unit”: “0”,
“prompt_price”: “0”,
“completion_tokens”: 5016,
“completion_unit_price”: “0”,
“completion_price_unit”: “0”,
“completion_price”: “0”,
“total_tokens”: 12620,
“total_price”: “0”,
“currency”: “USD”,
“latency”: 10.200757793150842
},
“finish_reason”: “length”,
“files”:
Thank you for sharing the additional details, we appreciate you providing the token usage and finish_reason information. This is helpful for our investigation.
We’ve confirmed your report and are working to diagnose the root cause of the truncation. If any further details are needed from your side, we’ll reach out immediately.
Thank you for your patience and collaboration.
Hello
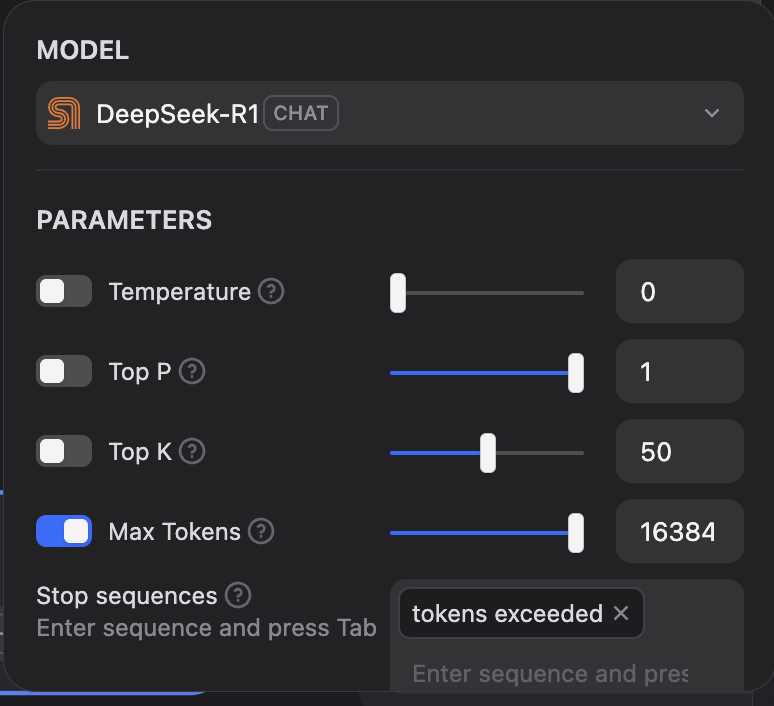
We replicated the issue you’re facing and found that there’s an option to set the Max Tokens parameter for the model in the Dify when creating workflow. By setting it to 16k, we were able to run a large prompt without encountering any sudden stoppages.
We recommend trying this setting to see if it resolves the issue for you. For your reference, we’ve included a screenshot below. If you continue to experience difficulties, please don’t hesitate to reach out to us, and we’ll be happy to assist you further.
Thank you for your patience
Thank for your reply.
I’ll try it.